

Key features for chDB, a powerful in-memory OLAP SQL Engine
Come learn about an exciting Clickhouse-powered alternative to DuckDB
Clickhouse is quickly becoming a crowd favorite real-time data warehouse platform for organizations looking to take advantage of blazing fast query speeds in OLAP scenarios that power mission-critical applications and embedded analytics.
It’s columnar storage mechanism that maximizes system resourcefulness allows it to be at least 100x faster at processing analytical queries than row-oriented spproaches. Recently, the Clickhouse team acquired the chDB project for running in-process SQL queries using a variety of formats and language bindings. In this post, we’re going to dive into why chDB is such a promising project for the clickhouse ecosystem and what it’s core use cases may be.
A DuckDB alternative
DuckDB has gained significant popularity as an in-process analytical database that excels at processing local datasets and running complex SQL queries without the need for a separate server process. Along that thread of thinking and inspiration, chDB positions itself as a compelling alternative that leverages Clickhouse’s proven columnar engine technology while offering a similar ease of use and deployment simplicity.
What sets chDB apart is its ability to handle massive datasets with the same performance characteristics as Clickhouse, making it particularly attractive for scenarios where data volume exceeds DuckDB’s sweet spot. In fact, chDB regularly outperforms DuckDB, Pandas, and Polars in benchmark queries.
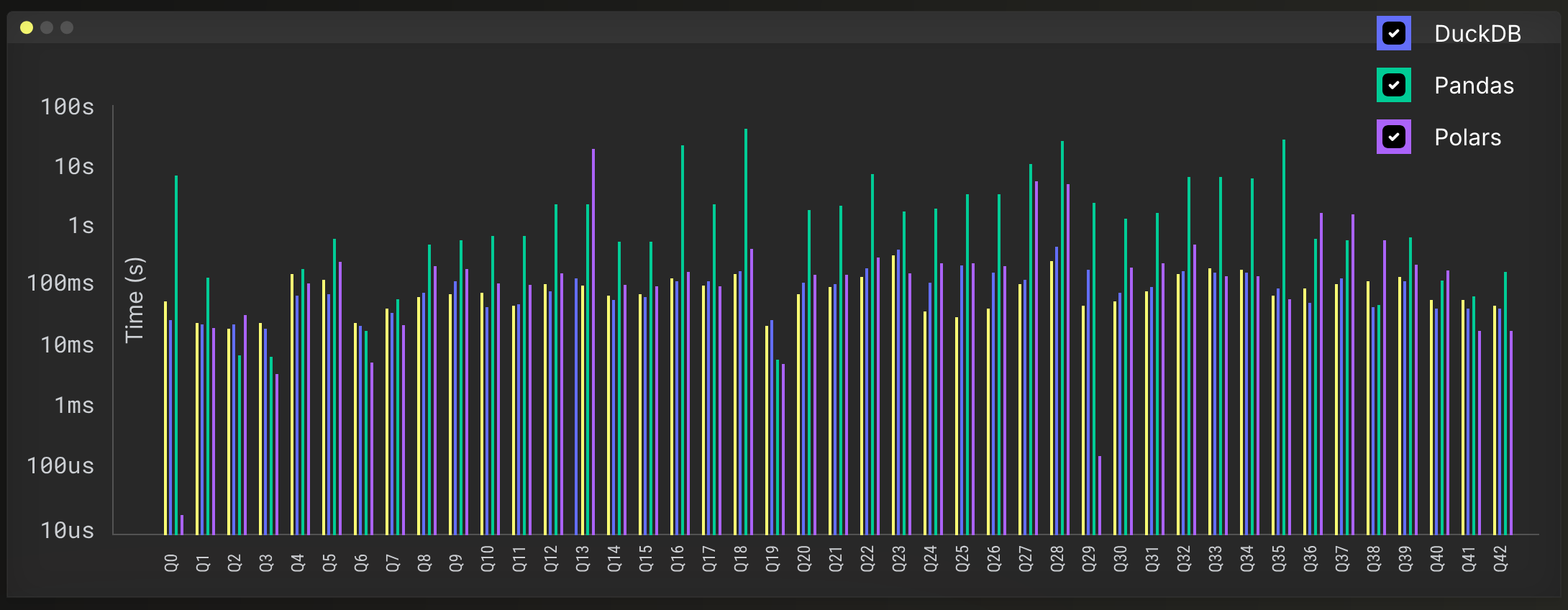
Why in-process SQL Engines are popping up
The rise of in-process SQL engines like chDB and DuckDB reflects a growing need for lightweight, embedded analytics capabilities that can operate directly within applications. As modern software architectures become more distributed and data-intensive, developers increasingly need powerful query engines that don’t require separate database servers or complex infrastructure. This shift towards embedded analytics is particularly evident in edge computing scenarios, serverless architectures, and applications requiring real-time data processing capabilities.
This trend is driven by several factors, including the need for reduced operational complexity, lower infrastructure costs, and the ability to process data closer to where it’s generated. In-process SQL engines provide a compelling solution by eliminating the need for separate database management while maintaining high performance. The combination of these factors has created fertile ground for innovations like chDB to flourish.
Use cases for chDB
chDB’s versatility makes it well-suited for several key use cases in modern data architectures. The project’s ability to handle large-scale data processing within the application process, combined with Clickhouse’s proven performance characteristics, opens up new possibilities for developers and data engineers. Let’s explore some of the most compelling use cases where chDB shines.
Local data pipelines
One of the primary use cases for chDB is building efficient local data pipelines. Its ability to process large datasets in-memory makes it ideal for ETL operations, data transformations, and preprocessing tasks that would traditionally require a full database setup. Developers can leverage chDB to perform complex SQL operations on local files, making it perfect for data scientists working with CSV files, JSON data, or Parquet formats. The seamless integration with popular programming languages like Python and Rust enables smooth workflow automation and rapid development of data processing scripts.
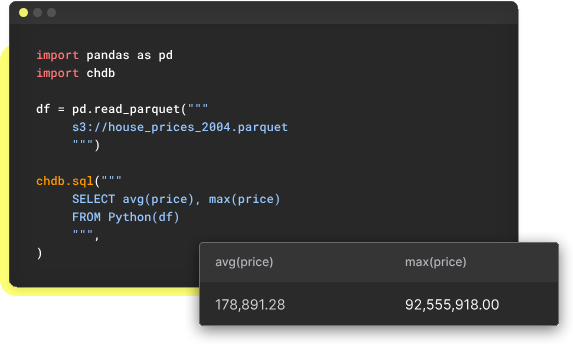
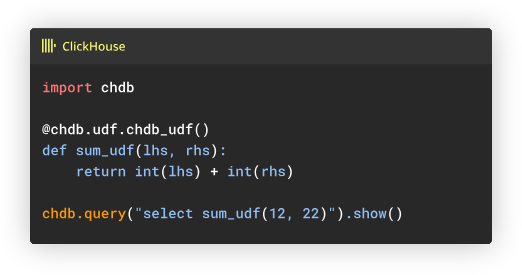
Serverless SQL Analytics
chDB has a variety of features that allow very efficient and direct querying of objects directly in-memory using features such as user-defined functions and almost 1:1 feature parity with Clickhouse.
This makes it particularly well-suited for serverless computing environments where spinning up a full database instance would be impractical or cost-prohibitive. Developers can embed chDB directly into their Lambda functions or serverless applications to perform complex analytics on data stored in cloud storage services like S3.
The ability to execute queries without maintaining persistent connections or managing database infrastructure significantly reduces operational overhead while maintaining high performance.
Using chDB: A in-process Data Pipeline Demo
Let’s explore a practical example of using chDB to build an efficient data pipeline that processes and analyzes a large dataset locally. In this demonstration, we’ll use Python to load a CSV file containing customer transaction data, perform some aggregations, and export the results - all using chDB’s powerful in-memory engine. This example will showcase chDB’s performance advantages and ease of use compared to traditional approaches.
import chdb
import pandas as pd
# Initialize chDB with our dataset
db = chdb.session()
data = pd.read_csv('transactions.csv')
# Execute complex aggregation query
result = db.query("""
SELECT
date_trunc('month', transaction_date) as month,
sum(amount) as total_sales,
count(distinct customer_id) as unique_customers
FROM data
GROUP BY month
ORDER BY month
""")
Features I’d love to see in chDB
While chDB is pretty amazing where it’s at, there’s a few things I’d love to see support for over time.
First, I’d love to see better support for materialized views and incremental aggregations. This would allow for more efficient caching of complex query results and better performance for frequently accessed data patterns. Additionally, expanded support for geospatial operations would open up exciting possibilities for location-based analytics directly within the application process.
Another feature on my wishlist would be enhanced integration with streaming data sources, allowing chDB to process real-time data streams while maintaining its impressive performance characteristics. This would make it even more valuable for real-time analytics applications and event processing scenarios.
Conclusion
chDB represents a significant step forward in the evolution of embedded analytics and data processing capabilities. By combining Clickhouse’s proven performance with the simplicity of an in-process engine, it offers developers a powerful tool for building modern data-intensive applications. As the project continues to mature and gain adoption, we can expect to see even more innovative use cases and implementations that push the boundaries of what’s possible with local data processing.
If you’d like to explore how we’re using chDB at Portcullis and how it can help you in your organization, schedule a free consultation.