

Why Portcullis is betting on Clickhouse for our petabyte-scale solution studio
Learn the thought process that went into staking our brand and business model on Clickhouse, the fastest OLAP database
At this point it’s fair to say we’re pretty bullish on Clickhouse, but if we learned anything from the recent trend cycle of AI-driven garbage takes and bandwagon product features it’s that you gotta have something to back up you bull 💩 if you’re going to be bullish. The nice thing about Clickhouse is that they make it super easy to set the differenciation between them and…colder options.
Clickhouse first popped up on our radar when Lauren Balik tweeted about the platform in a series of posts. Over time we started getting to know the platform and toolset through research and analysis to see what sets it apart from other options. When we first dove into it, the UI was nothing like it is today, and the continous improvement has been amazing to watch because their UI is superb.
So what went into our final decision to become so bullish on Clickhouse?
The Architecture
Clickhouse has a pretty great architectural layout which allows it to hit some pretty sleek metrics. On top of being a true column-oriented DBMS where no extra data is stored along with values, Clickhouse uses data compression to achieve excellent performance.
Storage Layer
Clickhouse’s core feature-set is powered by a family of table engines called the MergeTree family. They provide most features for resilience and high-performance data retrieval: columnar storage, custom partitioning, sparse primary index, secondary data-skipping indexes, etc. In the MergeTree engine, each table consists of multiple “parts”. A part is created whenever a user inserts data into the table (INSERT statement). A query is always executed against all table parts that exist at the time the query starts.
To avoid the issue of “Too many parts”, ClickHouse runs a merge operation in the background which continuously combines multiple (small) parts into a single bigger part. This approach has several advantages: On the one hand, individual inserts are “local” in the sense that they do not need to update global, i.e. per-table data structures.
Query processing layer
By using a vectorized query processing layer, Clickhouse can parallelize query execution as much as possible to utilize all resources for maximum speed and efficiency. If you’re not aware, “Vectorization” means that query plan operators pass intermediate result rows in batches instead of single rows. This leads to better utilization of CPU caches and allows operators to apply SIMD instructions to process multiple values at once.
The Speed
The core aspect of our decision-making process was the overall performance of Clickhouse compared to other data warehouses in the market.
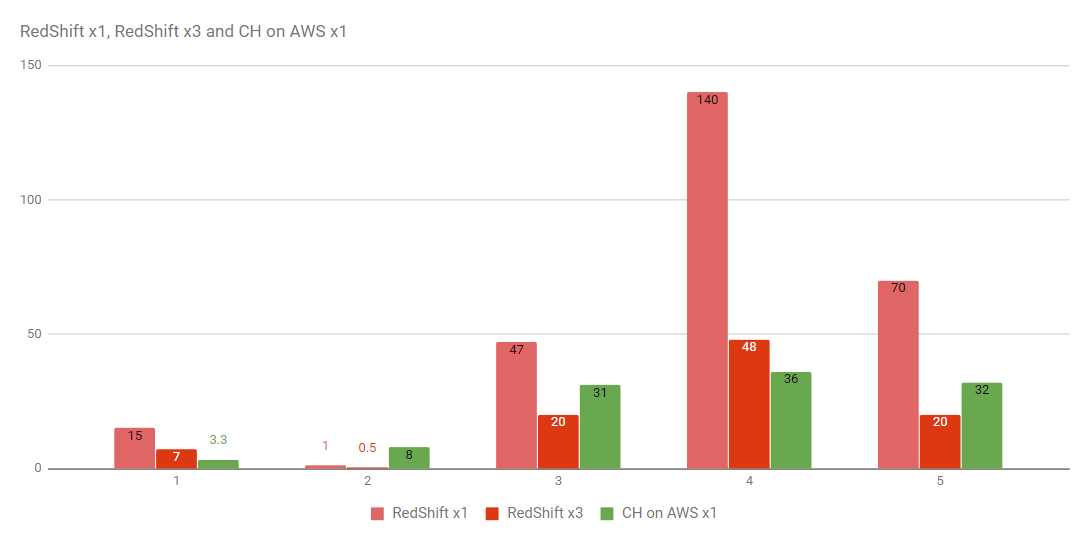
Clickhouse vs. Redshift
In 2017, Altinity did a benchmark comparing query performance of denormalized and normalized schemas using NYC taxi trips dataset.
Clickhouse vs. Snowflake
Snowflake is at a minimum 3x more expensive than ClickHouse Cloud when projecting costs of a production workload running these benchmark queries. To bring Snowflake to comparable performance to ClickHouse Cloud, Snowflake is 5x more expensive than ClickHouse Cloud for these production workloads.
Conclusion
With all that said, we’re super excited to tap into the Clickhouse ecosystem and start building tools and solutions that solve petabyte-scale problems for our stakeholders. If you’re curious about migrating to Clickhouse from another platform, or have a POC in mind that you need help with, get a free trial of our enterprise-grade support today!